In this post we are going check how Embedded Debezium can be used for CDC i.e. Change Data Capture.
What is CDC?
Change Data Capture (CDC) is a design pattern used in systems and applications to capture and track changes made to data in a database. It allows for the identification and delivery of changes made to data (such as insertions, updates, and deletions) to downstream processes, systems, or data warehouses. CDC is essential for real-time data integration and replication, enabling businesses to have up-to-date information for decision-making, analytics, and synchronization of systems.
CDC can be implemented in various ways, depending on the database management system (DBMS), the requirements of the application, and the infrastructure in place. Some common approaches include:
Database Triggers: Using triggers to capture changes to data at the time of modification. While this approach can be straightforward to implement, it can lead to increased load on the database since each change triggers a separate action.
Log-Based CDC: This method involves reading the database's transaction log (also known as the redo log or binary log, depending on the DBMS). Since databases log all transactions to ensure data integrity and recovery, this method allows capturing changes with minimal impact on the database performance. Log-based CDC is often considered more efficient and reliable, especially for high-volume databases.
Timestamp/Versioning: Adding timestamp or version fields to database records to track when data was last changed. This method requires polling the database to detect changes based on these fields. While simpler to implement, it can result in more significant database load and may not capture deletes effectively without additional logic.
Snapshot-Based CDC: This involves taking periodic snapshots of the database and comparing them to identify changes. This method can be resource-intensive and less timely than other approaches, making it less suitable for real-time data replication needs.
CDC is a crucial component of modern data architectures, especially in the context of big data, data warehousing, ETL (Extract, Transform, Load) processes, and business intelligence. It facilitates the efficient, real-time synchronization of data across different parts of an organization's data ecosystem, enabling more dynamic and responsive business strategies.
Advantages of CDC
Most companies today still use batch processing to sync data between their systems. Using batch processing:
- Data is not synced immediately
- More allocated resources are used for syncing databases
- Data replication only happens during specified batch periods
However, change data capture offers some advantages:
- Constantly tracks changes in the source database
- Instantly updates the target database
- Uses stream processing to guarantee instant changes
With CDC, the different databases are continuously synced, and bulk selecting is a thing of the past. Moreover, the cost of transferring data is reduced because CDC transfers only incremental changes.
In this post we are going to Use Embedded Debezium,
Debezium is an open-source platform for CDC built on top of Apache Kafka. Its primary use is to record all row-level changes committed to each source database table in a transaction log. Each application listening to these events can perform needed actions based on incremental data changes.
Debezium provides a library of connectors, supporting multiple databases like MySQL, MongoDB, PostgreSQL, and others.
These connectors can monitor and record the database changes and publish them to a streaming service like Kafka.
Deploying Debezium depends on the infrastructure we have, but more commonly, we often use Apache Kafka Connect.
Kafka Connect is a framework that operates as a separate service alongside the Kafka broker. We used it for streaming data between Apache Kafka and other systems.
We will be using the below Architecture:
Prerequisites To complete this example:
- An IDE
- JDK 11+ installed with JAVA_HOME configured appropriately
- Apache Maven 3.8.1+
- Docker Desktop
Let's Start :
1. We are going using Docker Desktop Docker Engine to Set up Source and Target Data Source. Docker Compose is used here,
Once Docker Compose is applied and up
The Same we can view at our IntelliJ Idea
Once Docker Engine is Up and Running We will be using MySql WorkBench as a DB Client here and create the DB Connections for Both Source and Target Data Sources.
Add the below Dependency in build.gradle file here we are using mysql connector.
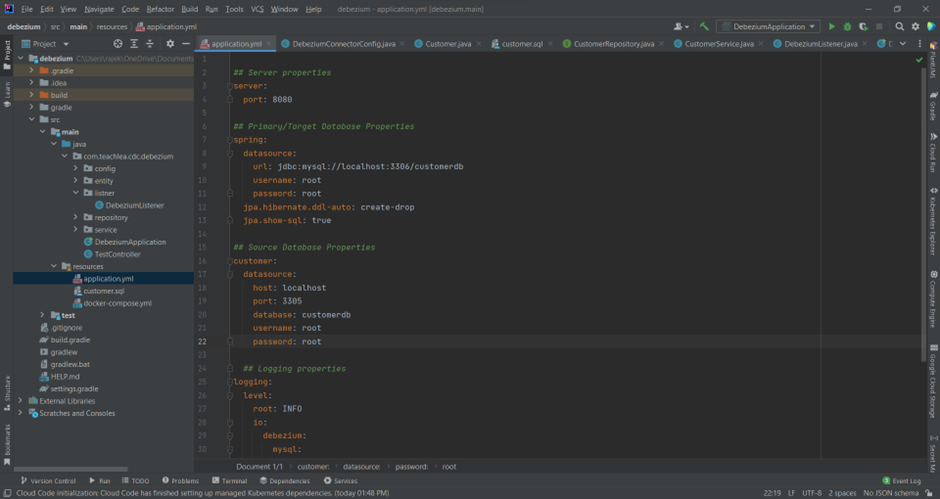
Add the datasource configuration details in application.yaml file.
Create
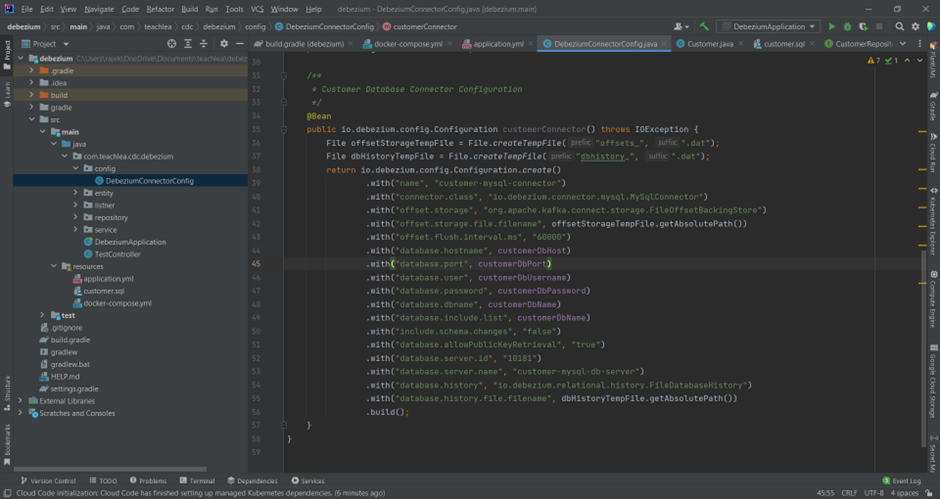
Debezium Config Class to configure our
Debezium MySQL Connector, we will create a Debezium configuration bean
The
DebeziumEngine serves as a wrapper around our MySQL connector. Let us create the engine using the connector configuration:
Now Start the Application, we will able to see
Debezium Engine will establish the mysql connectors.
Now It’s time check the
magic of
Debezium .
Check the Data in MySQL Source DB
Check Data in MySQL Target DB
Let us insert some date in Source DB
Check the Target DB at the same time without any delay the same data will be available in Target DB as shown below:
Now let us Update some date in the Source DB
The Same Update will happen in Target
Summary:
So in the Example we have seen and implemented how can we do Real Time Database Sync up with Change Data Capture using Embedded Debezium in Spring Boot Application.
Please feel free to provide your valuable comments, Thanks.




























0 Comments